Is X-Phi P-Hacked?
Mike Stuart, Edouard Machery and David Colaço

Scientists imagine a lot. They imagine to come up with new research problems, design experiments, interpret data, troubleshoot, draft papers and presentations, and give feedback to each other. But what kinds of imagination are used in science? When do scientists feel it is appropriate to employ imagination, and when not? How are the tricks of the imaginative trade taught?
Journals in psychology, neuroscience, and medicine pretty much only accept papers with significant p-values, usually setting the significance level at 0.05. Given that scientists are under immense pressure to publish often, and their papers will only be accepted if they report a p-value of 0.05 or lower, they may be tempted to make choices that help them reach this level.
Without cooking the data, a significant p-value can be obtained in a number of ways, collectively known as p-hacking: You can perform statistical testing midway through a study to decide whether to collect more data (“optional stopping”); you can simply collect masses of data and then perform statistical tests on your data until something shows up (“data dredging”); you can drop outliers or rearrange treatment groups post hoc, etc.
P-hacking is one of the main culprits for the replication crisis in psychology, neuroscience, and medicine. But what about experimental philosophy? Does it also suffer from p-hacking? In a paper just published in Analysis, David Colaço, Edouard Machery, and I examined a corpus of 365 experimental philosophy studies, which includes pretty much all the studies in x-phi from 1997 to 2016. We analyzed the p-values reported in these studies by p-curving them.
A p-curve plots the frequency of significant p-values in a set of studies. Roughly, if scientists are p-hacking in order to reach significance, they probably aren’t going to the trouble of making their p-values much lower than 0.05. So, if most of the p values in a series of studies are hovering right below significance, we have reason to be suspicious.
Once we have the p-curve, we can use its shape as an indicator of whether p-hacking has taken place (there are more sophisticated metrics lurking in the background, but the shape is a good proxy). If the curve starts high and slopes down as we move to the right, this tells us that most of the p-values are very low, and therefore some of the null hypotheses tested are false. If many p-values are at or near 0.05 (so the curve slopes up as we move toward p = 0.05), then scientists have engaged in p-hacking.
To illustrate, look at the figure below (taken from here). The black line displays a p-curve in which there are real effects, while the red line shows how the curve would look if p-hacking had taken place.

We produced p-curves for 2001-2006, 2006-2011, and 2011-2016, as well as p-curves for each subfield of experimental philosophy, papers co-authored with non-philosophers vs. philosophers only, and studies with small vs. large sample sizes. (In a recent blog post, we also produced p-curves for the corpora of specific philosophers, with their permission, just for fun).
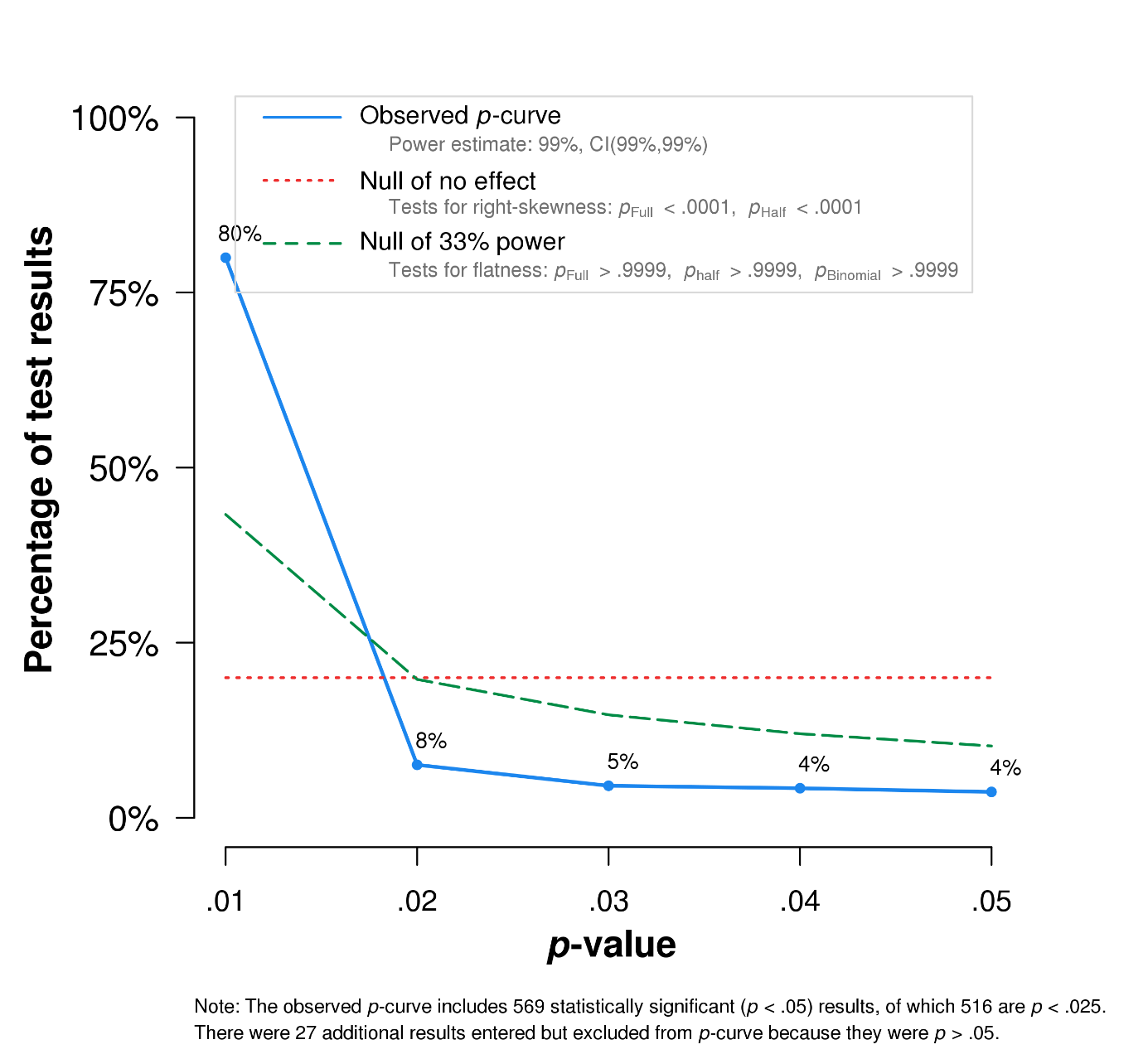
Here is the p-curve for the entire experimental philosophy corpus:
Here it is for just the first period (up to 2006):

And here it is for the most recent period in our dataset (2011-2016):
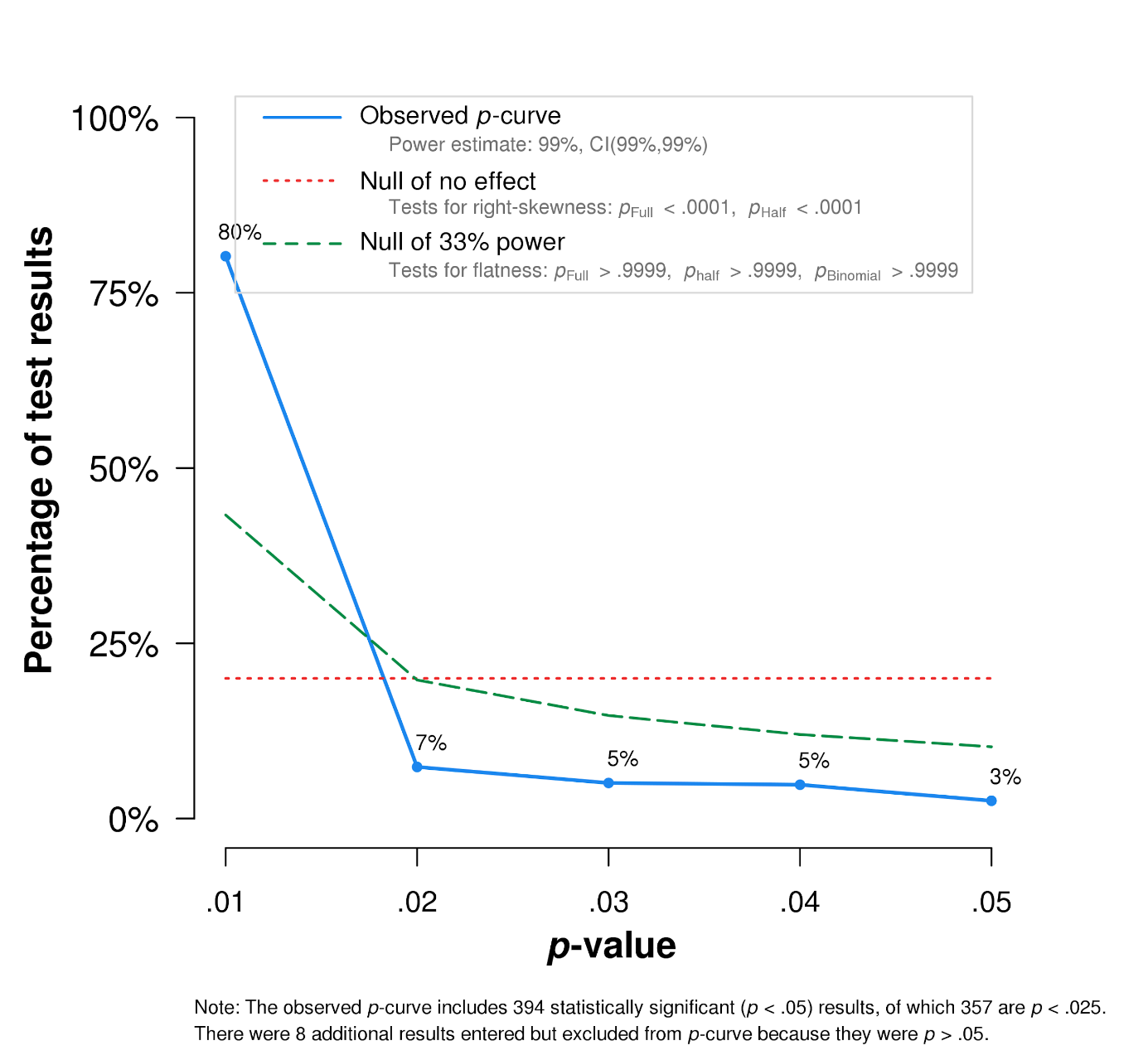
As we can see, early experimental philosophy does show evidence of p-hacking. Recent experimental philosophy does not. Also of note is that philosophers publishing on their own do no worse than they do when co-authoring with non-philosophers, papers published in collected volumes are no worse than those published in peer-reviewed journals, while studies with small sample sizes (n < 20) do appear to suffer from some p-hacking, while those with large sample sizes don’t.
Overall, the most important takeaway is probably that every subset we looked at, even those that appear to suffer from some p-hacking, had evidential value. That is, many of the null hypotheses tested are false and (very probably) many of the studies identify real effects. Impressions of methodological progress also appear at least partially justified. Experimental philosophy, it seems, has always been on to something (though what that something is is still up for debate).
(本文出自 DAILYNOUS)